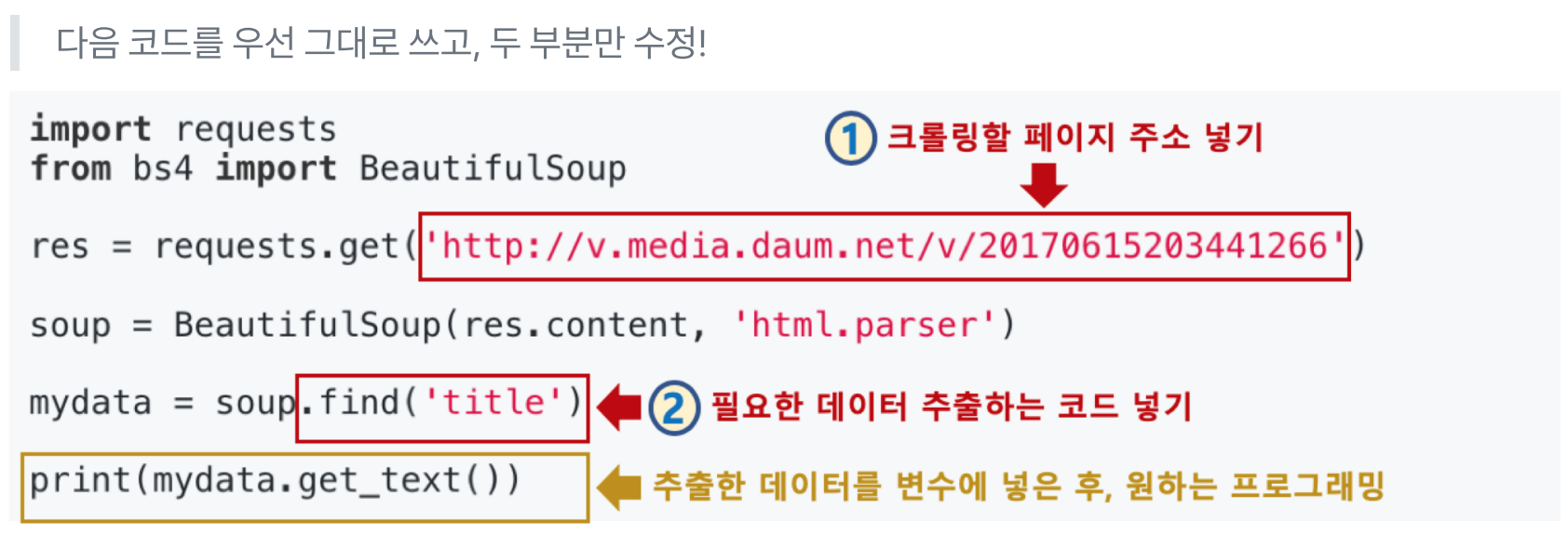
1. 라이브러리 import
필요 라이브러리
- requests
- bs4 (BeautifulSoup)
import requests
from bs4 import BeautifulSoup
2. 웹페이지 가져오기
HTML 파일 확인하기
- 웹브라우저로 확인
- 라이브러리로 확인
res = requests.get('http://~')
res.content # 해당 웹페이지의 HTML 파일 확인
3. 웹페이지 파싱하기
- 파싱: 문자열의 의미 분석
- BeautifulSoup 라이브러리를 이용하여 파일을 일일이 파싱한다.
soup = BeautifulSoup(res.content, 'html.parser')
⭐4. 필요한 데이터 추출하기
- soup.find() 함수로 원하는 부분을 지정하면 된다.
- 변수.get_text() 함수로 추출한 부분을 가져올 수 있다.
- 필요한 데이터를 변수에 넣으면 이후 활용은 프로그래밍 영역이다.
mydata = soup.find('title')
print(mydata.get_text())
