
1. 성능 데이터 모델링의 개요
성능 데이터 모델링
- 데이터베이스 성능을 고려하여 데이터 모델링을 수행하는 것
- 정규화, 반정규화, 테이블 통합/분할, 조인 구조, PK/FK 설정 등
- 수행 시점은 빠를수록 좋음 → 분석/설계 단계에서 성능 모델링 수행이 best
고려사항
- 데이터 모델링을 할 때 정규화를 정확하게 수행한다.
- 데이터베이스 용량 산정을 수행한다.
- 데이터베이스에 발생되는 트랜젝션의 유형을 파악한다.
- 용량과 트랜젝션의 유형에 따라 반정규화를 수행한다.
- 이력모델의 조정, PK/FK 조정, 슈퍼타입/서브타입 조정 등을 수행한다.
- 성능관점에서 데이터 모델을 검증한다.
2. 정규화와 성능
정규화
- 정규화는 데이터의 일관성, 최소한의 데이터 중복, 최소한의 데이터 유연성을 위해 데이터를 분해하는 과정
- 정규화된 모델은 분해된 테이블 (ex. 직원 테이블과 부서 테이블)간에 부서코드로 조인을 수행하여 하나의 합집합으로 만들 수 있다.
- 데이터 모델링을 하면서 정규화는 데이터 중복성을 제거하고, 데이터가 관심사별로 처리되는 경우가 많기 때문에 성능이 향상된다.
- 물론 엔터티가 계속 발생되므로 SQL 문장에서 조인이 많이 발생하여 이로 인한 성능저하가 나타나는 경우도 있지만, 이런 부분은 사례별로 유의하여 반정규화를 적용하는 전략이 필요하다.
- 정규화를 수행하는 것은 함수적 종속성에 기반하여 입력/수정/삭제 이상현상을 제거하는 것이다.

함수적 종속성
- 데이터들이 어떤 기준값에 의해 종속되는 현상을 지칭한다.
- 결정자와 종속자의 관계, 결정자의 값으로 종속자의 값을 알 수 있다.
- 결정자: 학번 / 종속자: 이름, 혈액형 (학번은 이름과 혈액형을 함수적으로 결정)
정규화의 효과
- 성능: 조회 / 입력,수정,삭제 2가지로 분류
- 데이터 중복 감소, 데이터가 관심사별로 묶임 → 성능 향상
- 데이터 조회(SELECT)에서 조인을 유발 → 성능 저하 (반정규화로 해결)
- 입력,수정,삭제의 경우 → 성능 향상
3. 반정규화와 성능
반정규화
- 정규화된 엔터티, 속성, 관계에 대해 성능 향상과 개발과 운영의 단순화를 위해 중복/통합/분리 등을 수행하는 데이터 모델링 기법
- 성능 향상을 위해 정규화된 데이터 모델에서 중복/통합/분리 등을 수행하는 모든 과정을 의미한다.
- 데이터 무결성이 깨질 수 있는 위험을 무릅쓰고 데이터를 중복하는 이유는 데이터를 조회할 때 디스크 I/O량이 많아서 성능이 저하되거나, 경로가 너무 멀어 조인으로 인한 성능 저하가 예상되거나, 칼럼을 계산하여 읽을 때 성능이 저하될 것이 예상되는 경우이다.

반정규화 기법
- 테이블 반정규화
- 테이블 병합: 1:1/1:M 관계 병합, 슈퍼타입/서브타입 병합
- 테이블 분할: 수직/수평 분할
- 테이블 추가: 중복 테이블/통계 테이블/이력 테이블/부분 테이블 추가
- 칼럼 반정규화
- 중복칼럼 추가
- 파생칼럼 추가
- 이력테이블 칼럼 추가
- PK에 의한 칼럼 추가
- 데이터 복구를 위한 칼럼 추가
- 관계 반정규화
- 중복 관계 추가
4. 대량 데이터에 따른 성능
- 일의 처리량이 한군데에 몰리는 현상은 어떤 업무에 있어서 중요한 업무에 해당되는 데이터가 특정 테이블에 있는 경우에 발생하게 되는데, 이 경우 트랜젝션이 분산 처리될 수 있도록 테이블 단위에서 분할 방법을 적용할 필요가 있다.
- 한 테이블에 대량의 데이터가 존재하는 경우 → 인덱스의 트리 구조가 너무 커져서 효율성이 떨어져 데이터를 처리할 때 디스크 I/O를 많이 유발하게 된다.
- 한 테이블에 많은 수의 칼럼이 존재하는 경우 → 데이터가 디스크의 여러 블록에 존재하므로 디스크에서 데이터를 읽는 I/O량이 많아져서 성능이 저하되게 된다.
- 대량의 데이터가 처리되는 테이블에서 성능이 저하되는 이유는 SQL 문장에서 데이터를 처리하기 위한 I/O량이 증가하기 때문이다.
- 조회조건에 따른 인덱스를 적절하게 이용하면 해당 테이블에 데이터가 아무리 많아도 원하는 데이터만 접근하면 되기 때문에 I/O량이 그닥 증가하지 않는다고 생각할 수도 있으나, 대량의 데이터가 하나의 테이블에 존재하게 되면 인덱스를 생성할 때 인덱스의 크기(용량)가 커지게 되고 인덱스를 찾아가는 단계가 깊어지게 되어 조회 성능에도 영향을 미치게 된다.
- 칼럼이 많아지는 경우는 물리적인 디스크에 여러 블록에 데이터가 저장되므로 데이터를 처리할 때 여러 블록에서 데이터를 I/O 해야하는 즉 SQL 문장의 성능이 저하될 수 있는 특징을 가진다.
- 로우체이닝: 로우 길이가 너무 길어서 데이터 블록 하나에 모든 데이터가 저장되지 않고 2개 이상의 블록에 걸쳐 하나의 로우가 저장되어 있는 형태
- 로우마이그레이션: 데이터 블록에서 수정이 발생하면 수정된 데이터를 해당 데이터 블록에서 저장하지 못하고 다른 블록의 빈 공간을 찾아 저장하는 방식
- 로우체이닝과 로우마이그레이션이 발생하여 많은 블록에 데이터가 저장되면 DB 메모리에서 디스크와 I/O가 발생할 때 불필요하게 많이 발생하여 성능이 저하된다.

해결 방안
- 한 테이블에 많은 칼럼 → 수직 분할 (칼럼 단위로 분할하여 I/O 경감)
- 대량 데이터 저장 문제 → 파티셔닝 (수평 분할), PK에 의한 테이블 분할
5. 데이터베이스 구조와 성능
슈퍼/서브타입 데이터 모델
이 모델은 업무를 구성하는 데이터 중 공통 부분을 슈퍼타입으로 모델링하고, 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성에 대해서는 별도의 서브엔터티로 구분하여 업무의 정확성과 물리적인 모델링을 할 때 선택의 폭을 넓히는 장점을 가진다.
슈퍼타입: 공통부분을 슈퍼타입으로 모델링
서브타입: 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성만 모델링
- 논리적 데이터 모델에서 주로 이용 (분석/설계 단계 중 분석에서 많이 쓰임)
- 물리적 데이터 모델 설계 시 슈퍼/서브타입 데이터 모델을 일정한 기준에 의해 변환을 해야하는데, 정확한 기준없이 막연하게 1:1로 변환하거나 하나의 테이블로 구성해버리면 성능 저하가 발생할 수 있다.

슈퍼/서브타입 데이터 모델 변환
해당 테이블에 발생되는 성능이 중요한 트랜젝션이 빈번하게 처리되는 기준에 따라 테이블을 설계해야 성능 저하를 예방할 수 있다. 슈퍼/서브타입을 성능을 고려한 물리적인 데이터 모델로 변환하는 기준은 데이터 양+해당 테이블에 발생되는 트랜젝션의 유형에 따라 결정된다.
- 개별로 발생되는 트랜젝션에 대해서는 개별 테이블로 구성
- 슈퍼+서브타입에 대해 발생되는 트랜젝션에 대해서는 슈퍼+서브타입 테이블로 구성
- 전체를 하나로 묶어 발생되는 트랜젝션에 대해서는 하나의 테이블로 구성

PK/FK 칼럼 순서와 성능
- PK/FK 칼럼 순서와 성능개요 데이터를 조회할 때 가장 효과적으로 처리되는 접근 경로를 제공하는 것은 바로 인덱스이다.
- 일반적인 프로젝트에선 PK/FK 칼럼 순서의 중요성을 인지하지 못한 채로 데이터 모델링이 되어있는 상태대로 바로 DDL을 생성하여 DB 데이터처리 성능에 문제를 유발하는 경우가 빈번하다.
- PK 순서를 인덱스의 특징을 고려하지 않고 그대로 생성하게 되면, 테이블에 접근하는 트랜젝션의 특징에 비효율적인 인덱스가 생성되어 있으므로 인덱스의 범위를 넓게 이용하거나 Full Scan을 유발하여 성능이 저하될 수 있다.
- 인덱스 엑세스 범위를 좁히는 가장 좋은 방법은 PK가 여러 개일 때, WHERE절에 사용하는 조건용 칼럼들이 우선순위가 되어야 한다.
6. 분산 데이터베이스와 성능
분산 데이터베이스
- 여러 곳으로 분산되어있는 데이터베이스를 하나의 가상 시스템으로 사용할 수 있게 만든 데이터베이스
- 논리적으로 동일한 시스템에 속하지만, 컴퓨터 네트워크를 통해 물리적으로 분산되어있는 데이터들의 모임
- 즉, DB를 연결하는 빠른 네트워크 환경을 이용하여 DB를 여러 지역 여러 노드로 위치시켜 사용성/성능 등을 극대화시킨 DB이다.
분산 DB의 투명성
- 분할 투명성 (단편화): 하나의 논리적 관계가 여러 단편으로 분할되어 각 단편의 사본이 여러 사이트에 저장
- 위치 투명성: 사용하려는 데이터의 저장 장소 명시가 불필요
- 지역사상 투명성: 지역 DBMS와 물리적 DB 사이의 사상이 보장
- 중복 투명성: DB 객체가 여러 사이트에 중복되어 있는지 여부를 몰라도 됨
- 장애 투명성: 구성요소(DBMS, 컴퓨터)의 장애에 무관하게 트랜젝션의 원자성이 유지됨
- 병행 투명성: 다수의 트랜젝션을 동시 수행했을 때 결과의 일관성이 유지됨
분산 DB의 장단점 및 적용방법
데이터를 분산시켰을 때 가장 핵심적인 가치는 바로 통합된 DB에서 제공할 수 없는 빠른 성능을 제공하는 것이다. 원거리 또는 다른 서버에 접속하여 처리하므로 발생하는 네트워크 부하 및 트랜젝션 집중에 따른 성능 저하의 원인을 해결하는 분산된 DB 환경을 구축하기 때문이다.

적용방법
- 테이블 위치 분산: 설계된 테이블의 위치를 각각 다르게 위치시킨다.

- 테이블 분할 분산: 각각의 테이블을 쪼개어(수평/수직) 분산한다.

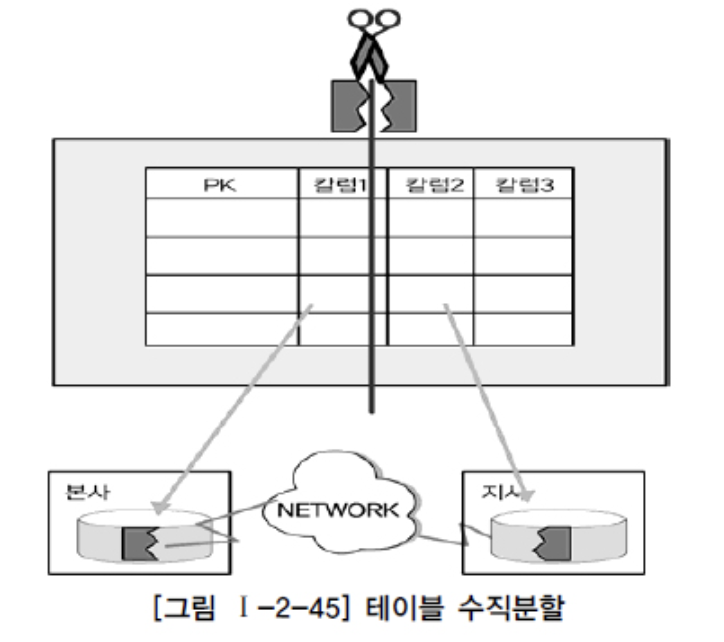
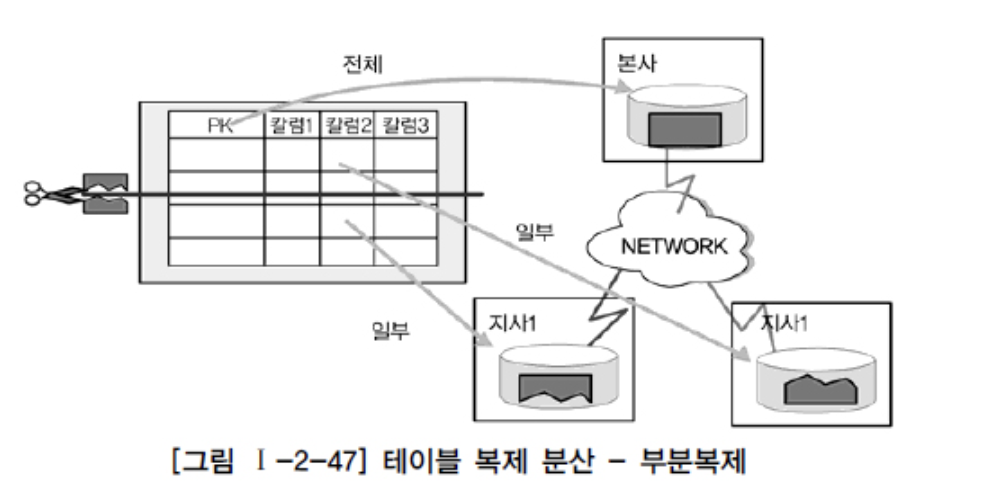
- 테이블 복제 분산: 통합된 테이블을 한곳에서 가지고 있으면서, 각 지사별로 지사에 해당하는 로우를 가지는 형태 (본사의 데이터는 지사데이터의 합)
- 테이블 요약 분산: 지역/서버간에 데이터가 비슷하지만 서로 다른 유형으로 존재하는 경우, 분산되어있는 동일한 내용의 데이터를 이용하여 통합된 데이터를 산출하는 방식(분석요약)과 분산되어있는 다른 내용의 데이터를 이용하여 통합된 데이터를 산출하는 방식(통합요약)

'SQLD' 카테고리의 다른 글
| 제약조건 (constraint) (0) | 2023.08.22 |
|---|---|
| 1) 데이터 모델링의 이해 (0) | 2023.08.08 |